前言 关于这篇文章起因,最近计划看一下《Effective Java》,然后我了解到此书的作者同样也是 Google Guava 库的作者,作为一个练习2年的 Java 的程序员,还没有研究过 Guava,属实有点说不过去,借此机会研究了一下 Google Guava。
先简单说一下 Google Guava 库,它不仅仅是 JDK 的升级库,诸如包含集合(collections)、缓存(caching)、并发库(concurrency libraries)、原生类型支持(primitives support)、字符串处理(string processing)、I/O 库等,还是《Effective Java》这本书中那些优秀经验的实践代表,两者应该结合起来阅读学习。在 Guava 中有两个实现我很感兴趣,一个是它实现的 Bloom Filter(布隆过滤器),另外一个就是本篇文章即将介绍的 RateLimiter(限流器)。
我们平时在开发高并发的分布式系统时,会借助许多手段来满足系统的并发要求,我总结下来大致分为下面几个方面:
缓存:通过缓存系统可以减少对底层数据存储系统的频繁访问,从而有效地提高系统的访问能力。从前端的浏览器,到网络,在到后端的服务,底层的数据库、文件系统、硬盘和CPU,全都都有设计缓存,这是提高快速访问能力的有效手段。
负载均衡:通过负载均衡可以将请求分摊到多个服务器上,避免单点故障和资源瓶颈,它是水平扩展的关键技术。
异步调用:异步调用的一个主要的技术手段就是消息队列,通过消息队列实现异步任务处理、系统解耦、削峰填谷等。
流量控制:通过限制系统等请求量和并发量,防止系统过载。常见的流量控制的手段包括限流、熔断和降级。
常见的限流实现方式 计数器算法 这是最基本、最粗暴的算法。一般来说,该算法会会维护一个计数器,当处理请求时,就对计数器做加一操作,当你请求处理完时,就对计数器做减一操作,如果计数器达到某个数量(预先设定的阀值),则按照限流的规则处理,防止系统过载。
采用队列的算法 这个算法有点像 FIFO,请求有快有慢,所有的请求都放入队列中,消费端以固定的速率从消息队列中取出请求消费,从而控制整个系统的处理流量,以下就是这个算法的示意图:
当然,我们可以在上面这个算法的基础上,延伸出其他更为高阶的用法,例如利用优先级队列实现一个具有优先级的流量控制算法。例如针对不同的请求,处理时先处理优先级高的队列,等优先级高的队列处理完了再处理优先级低的队列;再比如,还可以设置不同的权重,根据队列的权重处理来先后处理不同的请求。
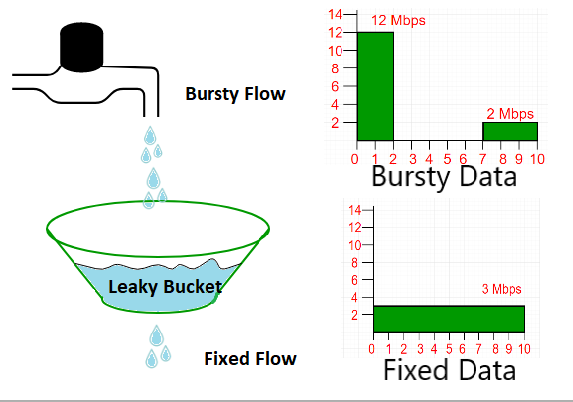
漏桶(Leaky Bucket)算法 关于漏桶,wikipedia上有关于它的词条 。
漏桶算法,就像一个漏斗一样,如果把进入漏斗的水比做进入的流量,那么从漏斗中漏出的水就是系统处理的流量。进入漏斗中的流量可快可慢,但是经过漏斗,流量都会以一个固定的速率流出,如果遇到突发流量,超过了漏斗的最大容量,则会丢弃流量,通过这种方式,可以保护系统,防止系统被突发的大流量冲垮。
关于漏桶算法的实现,一个比较常见的实现方式就是利用 FIFO 队列。把数据包放入 FIFO 队列中,如果流量都以固定大小的数据包组成,则在该进程的时钟每次 tick 时,从队列中移除该固定长度的数据用于消费;如果流量是以可变长度大小的数据包组成,则每次对队列中的数据进行消费时依赖于字节或者比特的数量。
下面就是一个处理可变长度数据包流量的算法:
在时钟tick时初始化一个计数器n
重复下面的操作直到n小于队列头部数据包的数据大小
从队列头部弹出一个数据包,计做P
将数据包P发出
将计数器n减少数据包P的长度
重置计数器n,重复步骤1
代码大致逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class VariableLenPacketDemo { public static void main (String[] args) { int storage = 0 ; int bucketSize = 10 ; int inputPktSize = 4 ; int outPktSize = 1 ; int numberQueries = 4 ; for (int i = 0 ; i < numberQueries; i++) { int leftSize = bucketSize - storage; if (inputPktSize <= leftSize) { storage += inputPktSize; } else { System.out.println("packet loss = " + inputPktSize); } System.out.println("buff size = " + storage + " out of bucket size = " + bucketSize); storage -= outPktSize; } } }
关于漏桶算法,以下是一个完整的算法demo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 public class LeakyBucket { private int bucketSize; private int leakRate; private int currentPacket; private Queue<Packet> queue; public LeakyBucket (int bucketSize, int leakRate) { this .bucketSize = bucketSize; this .leakRate = leakRate; this .currentPacket = 0 ; this .queue = new ArrayDeque <>(); } public boolean addPacket (int packetSize) { if (this .currentPacket + packetSize <= this .bucketSize) { this .queue.add(new Packet (packetSize, System.currentTimeMillis())); this .currentPacket += packetSize; return true ; } else { return false ; } } public void leak () { while (!this .queue.isEmpty()) { Packet packet = this .queue.peek(); long timeElapsed = System.currentTimeMillis() - packet.getArrivalTime(); int leakPacket = (int ) (timeElapsed * leakRate / 1000 ); if (leakPacket >= packet.getPktSize()) { this .queue.poll(); this .currentPacket -= packet.getPktSize(); } else { break ; } } } } public class Packet { private int pktSize; private long arrivalTime; public Packet (int pktSize, long arrivalTime) { this .pktSize = pktSize; this .arrivalTime = arrivalTime; } public long getArrivalTime () { return arrivalTime; } public int getPktSize () { return pktSize; } } public class Main { public static void main (String[] args) throws InterruptedException { int bucketSize = 100 ; int leakRate = 10 ; LeakyBucket leakyBucket = new LeakyBucket (bucketSize, leakRate); int [] packets = {20 , 30 , 10 , 50 , 40 }; for (int packetSize : packets) { if (leakyBucket.addPacket(packetSize)) { System.out.println("packet length " + packetSize + " has been add the leaky bucket" ); } else { System.out.println("leaky bucket full, packet length " + packetSize + " has been dropped" ); } leakyBucket.leak(); Thread.sleep(1000 ); } } }
令牌桶(Token Bucket)算法 关于令牌桶算法,可以参考维基百科的词条:令牌桶 。令牌桶算法是有一个中间代理人,以固定的速率往一个桶(Bucket)内放入令牌,只有拿到令牌的请求才能进行消费。和漏桶算法都以一个固定的速率消费不同,令牌桶算法在流量不是很大时放桶内放入令牌,在流量大时,可以以较快的速率消费(只要桶内的令牌足够)。
以下是一个令牌桶算法实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 type TokenBucket struct { rate int64 maxTokens int64 currentTokens int64 lastRefillTmestamp time.Time mutex sync.Mutex } func NewTokenBucket (Rate int64 , MaxTokens int64 ) return &TokenBucket{ rate: Rate, maxTokens: MaxTokens, lastRefillTmestamp: time.Now(), currentTokens: MaxTokens, } } func (tb *TokenBucket) now := time.Now() end := time.Since(tb.lastRefillTmestamp) tokensTobeAdded := (end.Nanoseconds() * tb.rate) / 1000000000 tb.currentTokens = int64 (math.Min(float64 (tb.currentTokens+tokensTobeAdded), float64 (tb.maxTokens))) tb.lastRefillTmestamp = now } func (tb *TokenBucket) int64 ) bool { tb.mutex.Lock() defer tb.mutex.Unlock() tb.refill() if tb.currentTokens >= tokens { tb.currentTokens = tb.currentTokens - tokens return true } return false }
应用 在许多的开源框架和工具中,都实现了 Token Bucket(令牌桶)算法,例如一个比较常见的例子就是 Google Guava实现的 RateLimiter。RateLimiter 是一个限流工具,基于令牌桶算法实现,可以控制某个时间段内控制请求的数量。
从使用上来看,Google Guava 的限流器使用非常简单,只需要创建一个 RateLimiter 对象,并调用它的 acquire 方法即可。acquire 方法会阻塞调用线程,自到获取令牌为止。
1 2 3 4 5 6 7 8 RateLimiter limiter = RateLimiter.create(10.0 );while (true ) { limiter.acquire(); handleRequest(); }
在下面的例子中,我创建了一个流速为 2 个请求/秒的限速器,从直观上来看,这里的流速指的是每秒最多允许 2 个请求通过限流器,在 Guava 中,这里其实是一种匀速的概念,2 个请求/秒等价于1一个请求/500毫秒,在向线程池提交任务之前,调用 acquire() 方法就能起到限流的作用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 RateLimiter limiter = RateLimiter.create(2.0 ); ExecutorService es = Executors .newFixedThreadPool(1 ); prev = System.nanoTime(); for (int i=0 ; i<20 ; i++){ limiter.acquire(); es.execute(()->{ long cur=System.nanoTime(); System.out.println( (cur-prev)/1000_000 ); prev = cur; }); } 输出结果: ... 500 499 499 500 499
Google Guava RateLimiter实现原理分析 Guava RateLimiter 使用的是令牌桶算法,在分析原理之前,我们再来描述一下令牌桶算法:
令牌以固定的速率添加到令牌桶中,假设限流的速率是 r/ 秒,则令牌每 1/r 秒会添加一个;
假设令牌桶的容量是 b,如果令牌桶已满,则新的令牌会丢弃;
请求能够通过限流器的前提是令牌桶中有令牌。
上面我们解释了流速 r,它其实是一种匀速的概念,那么令牌桶的容量 b 该怎么理解呢?b 其实是 burst 的缩写,意义是限流器允许的最大突发流量。比如 b=10,并且桶中的令牌已满,此时限流器允许 10 个请求同时通过限流器,当然只是突发流量而已,这 10 个请求会带走 10 个令牌,所以后续的流量只能按照速率 r 通过限流器。
以下涉及到源码分析,本文使用的 Guava 版本是截止目前最新的31.1-jre版本。
前面讲到,RateLimiter的使用非常简单,它有两个静态方法用来实例化,实例化以后,我们只需要关心 acquire 就行了,甚至都没有 release 操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static RateLimiter create (double permitsPerSecond) {}public static RateLimiter create (double permitsPerSecond, long warmupPeriod, TimeUnit unit) {}public double acquire () {}public double acquire (int permits ) {}public boolean tryAcquire () {}public boolean tryAcquire (int permits ) {}public boolean tryAcquire (long timeout, TimeUnit unit) {}public boolean tryAcquire (int permits , long timeout, TimeUnit unit) {}public final double getRate () {}public final void setRate (double permitsPerSecond) {}
我们知道,Java 并发包中提供了 Semaphore,它也能够对资源访问进行控制,不同的是,Semaphore 控制的是并发的数量,而 RateLimiter 是用来控制资源访问的速率(rate)的,它强调的是控制速率。
可以看到,create 方法指定一个 permitsPerSecond 参数,代表每秒钟产生多少个 permits,这就是速率。RateLimiter允许预占未来的令牌,比如,每秒钟产生5个 permits,我们可以单次请求 100 个 permits,这样,紧接着的下一个请求需要等待大概 20 秒才能获取到 permits。
SmoothRateLimiter介绍 通过源码可以看到,RateLimiter只有一个子类,就是抽象类 SmoothRateLimiter,SmoothRateLimiter 有两个实现类,其实就是对应了限流器的两种模式,这里先介绍一下中间的抽象类 SmoothRateLimiter,然后后面分别介绍它的两个实现类(对应的两种模式)。
RateLimiter 作为抽象类,它只有两个属性
1 2 3 private final SleepingStopwatch stopwatch;private volatile Object mutexDoNotUseDirectly;
其中,stopwatch非常重要,它是一个底层计时器,用它来“计时”,RateLimiter 把实例化的时间设置为 0 值,后续都是取相对时间,用微秒表示。
mutexDoNotUseDirectly 用来做锁,RateLimiter 依赖于 synchronized 来控制并发,所以我们其实可以看到,它的各个属性都没没有用 volatile 修饰。
具体看抽象类 SmoothRateLimiter 源码,可以看到它有如下属性:
1 2 3 4 5 6 7 8 9 10 11 12 double storedPermits;double maxPermits;double stableIntervalMicros;private long nextFreeTicketMicros = 0L ;
nextFreeTicketMicros 是一个很重要的属性。我们每一次获取 permits 的时候,先拿 storedPermits 的值,因为它是当前存下来的 permits,如果当前存的 permits 够,storedPermits 减去请求消耗的 permits 就可以了,如果不够,那么就需要将这个 nextFreeTicketMicros 的时间往前推,表示预占了接下来多少时间的 permits。那么如果在下一个请求到来的时候,如果还没有到 nextFreeTicketMicros 这个时间点,需要 sleep 到这个时间点再返回,当然也需要再将这个时间往前推。
这里可能有个疑问:因为时间是一直在往前走的,应该要一直往池中添加 permits,所以 storedPermits 的值需要不断的往上添加,难道需要另外开启一个线程来单独完成这个事情吗?其实不是的,只需要在关键的操作中同步一下,然后重新计算 permits 就好了。
SmoothBursty 分析 查看源码,RateLimiter 有一个公有的静态 create 方法:
1 2 3 public static RateLimiter create (double permitsPerSecond) { return create(permitsPerSecond, SleepingStopwatch.createFromSystemTimer()); }
参与 permitsPerSecond 表示每秒钟可以产生多少个 permits,其中调用了如下方法
1 2 3 4 5 static RateLimiter create (double permitsPerSecond, SleepingStopwatch stopwatch) { RateLimiter rateLimiter = new SmoothBursty (stopwatch, 1.0 ); rateLimiter.setRate(permitsPerSecond); return rateLimiter; }
这里实例化的是 SmoothBursty 的实例,顺着代码点进去,发现它只有一个属性 maxBurstSeconds,在实例化的时候,指定了 maxBurstSeconds 为 1.0,也就是说,最多会缓存 1 秒钟,也就是 (1.0 * permitsPerSecond)这么多个 permits 到池中。
这个 1.0 秒,还关系到 storedPermits 和 maxPermits:
0 <= storedPermits <= maxPermits = permitsPerSecond
继续往下看 setRate 方法:
1 2 3 4 5 6 7 public final void setRate (double permitsPerSecond) { checkArgument( permitsPerSecond > 0.0 && !Double.isNaN(permitsPerSecond), "rate must be positive" ); synchronized (mutex()) { doSetRate(permitsPerSecond, stopwatch.readMicros()); } }
setRate 是一个 public 方法,可以用它来调整速率。继续看初始化的过程,这里使用了 synchronized 来控制并发。往下跟踪可以看到子类抽象类 SmoothRateLimiter 中重写了这个方法:
1 2 3 4 5 6 7 8 9 @Override final void doSetRate (double permitsPerSecond, long nowMicros) { resync(nowMicros); double stableIntervalMicros = SECONDS.toMicros(1L ) / permitsPerSecond; this .stableIntervalMicros = stableIntervalMicros; doSetRate(permitsPerSecond, stableIntervalMicros); }
Resend 方法用来调整 storesPermits 和 nextFreeTicketMicros。这就是我在上面说的,不需要单独开启一个线程增加 storedPermits 的值,在关键的步骤节点,需要先更新一下 storedPermits 到正确的值。
1 2 3 4 5 6 7 8 9 void resync (long nowMicros) { if (nowMicros > nextFreeTicketMicros) { double newPermits = (nowMicros - nextFreeTicketMicros) / coolDownIntervalMicros(); storedPermits = min(maxPermits, storedPermits + newPermits); nextFreeTicketMicros = nowMicros; } }
上述的源码中,coolDownIntervalMicros() 这个方法可以先不用关注,可以看到,在子类 SmoothBursty 类中的实现是直接返回了 stableIntervalMicros 的值,也就是我们说的,每产生一个 Permits 的时间长度。
看到这里不难发现,在 resync 的时候,此时的 stableIntervalMicros 其实并没有设置,是在下面的 doSetRate 的实现中设置的,也就是说这里发生了一次除 0 的操作,得到的结果其实是无穷大。而此时 maxPermits 还是 0,不过这里没有多大关系。
再回到前面的 doSetRate 方法,可以看到 resync 以后,会走到下面的 doSetRate逻辑,这里子类 SmoothBursty 的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Override void doSetRate (double permitsPerSecond, double stableIntervalMicros) { double oldMaxPermits = this .maxPermits; maxPermits = maxBurstSeconds * permitsPerSecond; if (oldMaxPermits == Double.POSITIVE_INFINITY) { storedPermits = maxPermits; } else { storedPermits = (oldMaxPermits == 0.0 ) ? 0.0 : storedPermits * maxPermits / oldMaxPermits; } }
上面就是实例化 SmoothBursty 的一个过程,接下来再来分析 acquire 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @CanIgnoreReturnValue public double acquire () { return acquire(1 ); } @CanIgnoreReturnValue public double acquire (int permits ) { long microsToWait = reserve(permits ); stopwatch.sleepMicrosUninterruptibly(microsToWait); return 1.0 * microsToWait / SECONDS.toMicros(1L ); }
继续看 reserve 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 final long reserve(int permits) { checkPermits(permits); synchronized (mutex()) { return reserveAndGetWaitLength(permits, stopwatch.readMicros()); } } final long reserveAndGetWaitLength(int permits, long nowMicros) { // 返回 nextFreeTicketMicros long momentAvailable = reserveEarliestAvailable(permits, nowMicros); // 计算时长 return max(momentAvailable - nowMicros, 0); }
顺着代码继续往里看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Override final long reserveEarliestAvailable (int requiredPermits, long nowMicros) { resync(nowMicros); long returnValue = nextFreeTicketMicros; double storedPermitsToSpend = min(requiredPermits, this .storedPermits); double freshPermits = requiredPermits - storedPermitsToSpend; long waitMicros = storedPermitsToWaitTime(this .storedPermits, storedPermitsToSpend) + (long ) (freshPermits * stableIntervalMicros); this .nextFreeTicketMicros = LongMath.saturatedAdd(nextFreeTicketMicros, waitMicros); this .storedPermits -= storedPermitsToSpend; return returnValue; }
可以看到获取 permits 的时候,其实是获取了两部分,一部分来自于存量 storedPermits,存量不够的话,另一部分来自于预占未来的 freshPermits。这里有一个关键点,可以看到上面方法的返回值是 nextFreeTicketMicros 的旧值,因为只要到这个时间节点,就说明在当次 acquire 可以成功返回了,而不管 sroredPermits 够不够,如果不够,会将 nextFreeTicketMicros 往前推一定的时间,预占了一定的量。
SmoothWarmingUp 分析 下面再来看 Guava 限流器的另外一种模式。SmoothWarmingUp 适用于资源需要预热的场景,比如某个接口的业务需要使用到数据库连接,由于连接需要预热才能进入到最佳状态,如果我们的系统长时间处于低负载或零负载状态,连接池中的连接慢慢释放掉了,此时我们认为连接池是冷的。假设业务在稳定状态下,正常可以提供最大 1000 QPS 的访问,但是如果连接池是冷的,我们就不能让系统达到 1000 的QPS,要限制住突发流量,因为这会拖垮后端数据库,从而拖垮整个系统,应该有一个预热的过程。这里我先贴一个 Guava 源码中 SmoothWarmingUp 的注释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
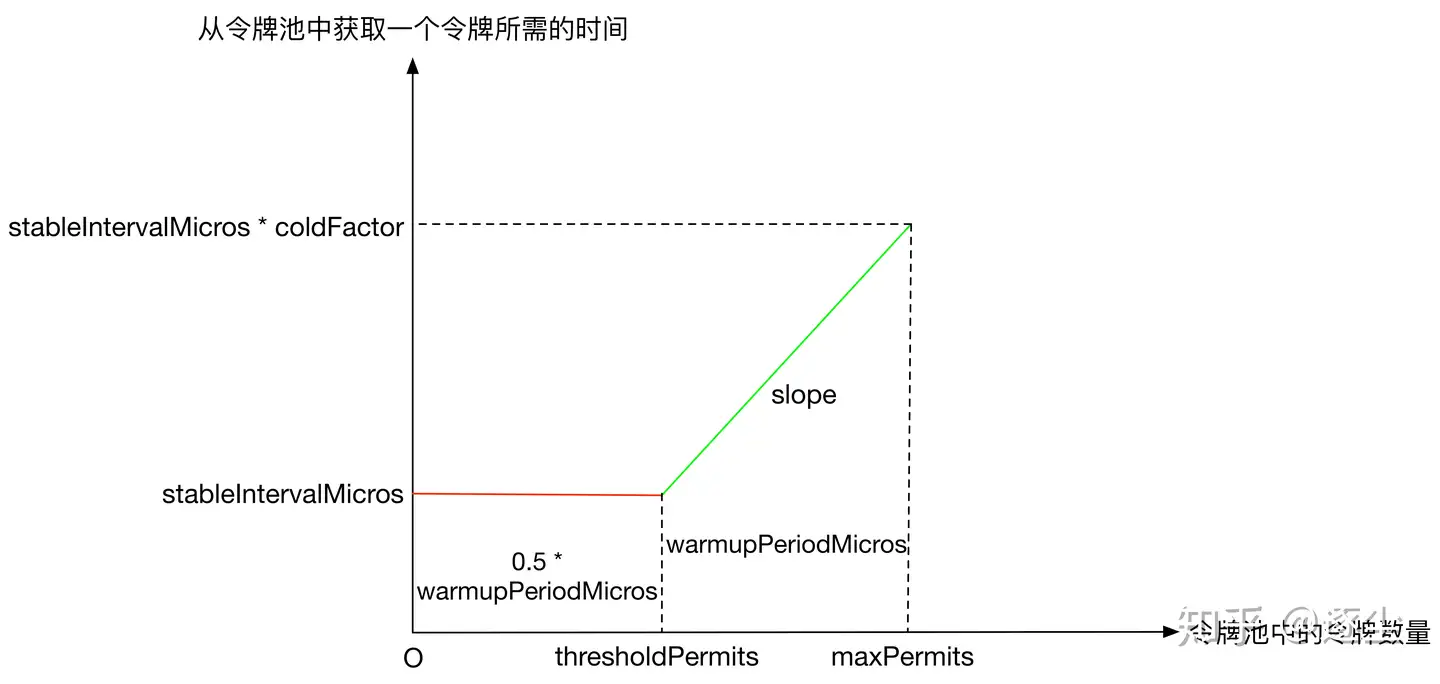
可以看到 X 轴代表 storedPermits 的数量,Y 轴代表获取一个 permits需要的时间。如果系统处于低负载的状态,storedPermits 会一直增加,当请求来的时候,我们要从 storedPermits 中取 permits,在这种模式下,如果 storedPermits越大,代表系统越冷,则获取 permits 需要的时间就越多。这里回顾一下上面介绍的 SmoothBursty 模式,它从 storedPermtis 中获取 permits 是不需要等待时间的,而 SmoothWarmingUp 恰恰相反。这里大致总结一下 SmoothBursty 和 SmoothWarmingUp 的区别:
SmoothBursty 初始化的时候令牌池中的令牌数量为 0,而 SmoothWarmingUp 初始化的时候令牌池数量为 maxPermits。 SmoothBursty 从令牌池中获取令牌不需要等待,而 SmoothWarmingUp 从令牌池中获取令牌需要等待一段时间,该时间长短和令牌池中的令牌数量有关系
这里我在网上找到了一个更详细的图对此预热过程进行说明:
上图中 slope 表示绿色实线的斜率,其计算方式如下:
1 slope = (stableIntervalMicros * coldFactor - stableIntervalMicros) / (maxPermits - thresholdPermits)
由于横坐标表示令牌桶中令牌使用,纵坐标表示从令牌桶中获取一个令牌需要的时间,则红色实线对应的矩形面积、绿色实线对应的梯形面积都代表时间,因此预热时间 warmupPeriodMicros的定义如下(梯形面积):从满状态的令牌桶中取出(maxPermits - thresholdPermits)个令牌所需花费的时间。预热时间是我们在构造的时候指定的,完成预热后,我们能进入到一个稳定的速率中(stableInterval)。有一个关键的点是从 thresholdPermits 到 0 的时间,是从 maxPermits 到 thresholdPermits 时间到一半,也就是梯形面积是长方形面积的 2 倍,至于具体原因,可以自行论证。下面就是根据构造参数计算出 thresholdPermits 和 maxPermits 的值。
梯形面积为 warmupPeriod,而长方形面积为 stableInterval * thresholdPermits,即:
1 warmupPeriod = 2 * stableInterval * thresholdPermits
由此可以得出 thresholdPermits 的值:
1 thresholdPermits = 0.5 * warmupPeriod / stableInterval
然后根据梯形面积公式:
1 warmupPeriod = 0.5 * (stableInterval + coldInterval) * (maxPermits - thresholdPermits)
可以得出 maxPermits 为:
1 maxPermits = thresholdPermits + 2.0 * warmupPeriod / (stableInterval + coldInterval)
这样我们就算出了 thresholdPermits 和 maxPermits 的值。
下面再来看一下冷却时间间隔,它指的是 sroredPermits 中每个 permits 的增长速度,为了达到从 0 到 maxPermits 花费 warmupPeriodMicros 的时间,在源码中将其定义为:
1 2 3 4 @Override double coolDownIntervalMicros () { return warmupPeriodMicros / maxPermits; }
它在 resync 中有使用:
1 2 3 4 5 6 7 8 void resync (long nowMicros) { if (nowMicros > nextFreeTicketMicros) { double newPermits = (nowMicros - nextFreeTicketMicros) / coolDownIntervalMicros(); storedPermits = min(maxPermits, storedPermits + newPermits); nextFreeTicketMicros = nowMicros; } }
接着来看它的 doSetRate 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Override void doSetRate (double permitsPerSecond, double stableIntervalMicros) { double oldMaxPermits = maxPermits; double coldIntervalMicros = stableIntervalMicros * coldFactor; thresholdPermits = 0.5 * warmupPeriodMicros / stableIntervalMicros; maxPermits = thresholdPermits + 2.0 * warmupPeriodMicros / (stableIntervalMicros + coldIntervalMicros); slope = (coldIntervalMicros - stableIntervalMicros) / (maxPermits - thresholdPermits); if (oldMaxPermits == Double.POSITIVE_INFINITY) { storedPermits = 0.0 ; } else { storedPermits = (oldMaxPermits == 0.0 ) ? maxPermits : storedPermits * maxPermits / oldMaxPermits; } }
然后再来回顾一下下面的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Override final long reserveEarliestAvailable (int requiredPermits, long nowMicros) { resync(nowMicros); long returnValue = nextFreeTicketMicros; double storedPermitsToSpend = min(requiredPermits, this .storedPermits); double freshPermits = requiredPermits - storedPermitsToSpend; long waitMicros = storedPermitsToWaitTime(this .storedPermits, storedPermitsToSpend) + (long ) (freshPermits * stableIntervalMicros); this .nextFreeTicketMicros = LongMath.saturatedAdd(nextFreeTicketMicros, waitMicros); this .storedPermits -= storedPermitsToSpend; return returnValue; }
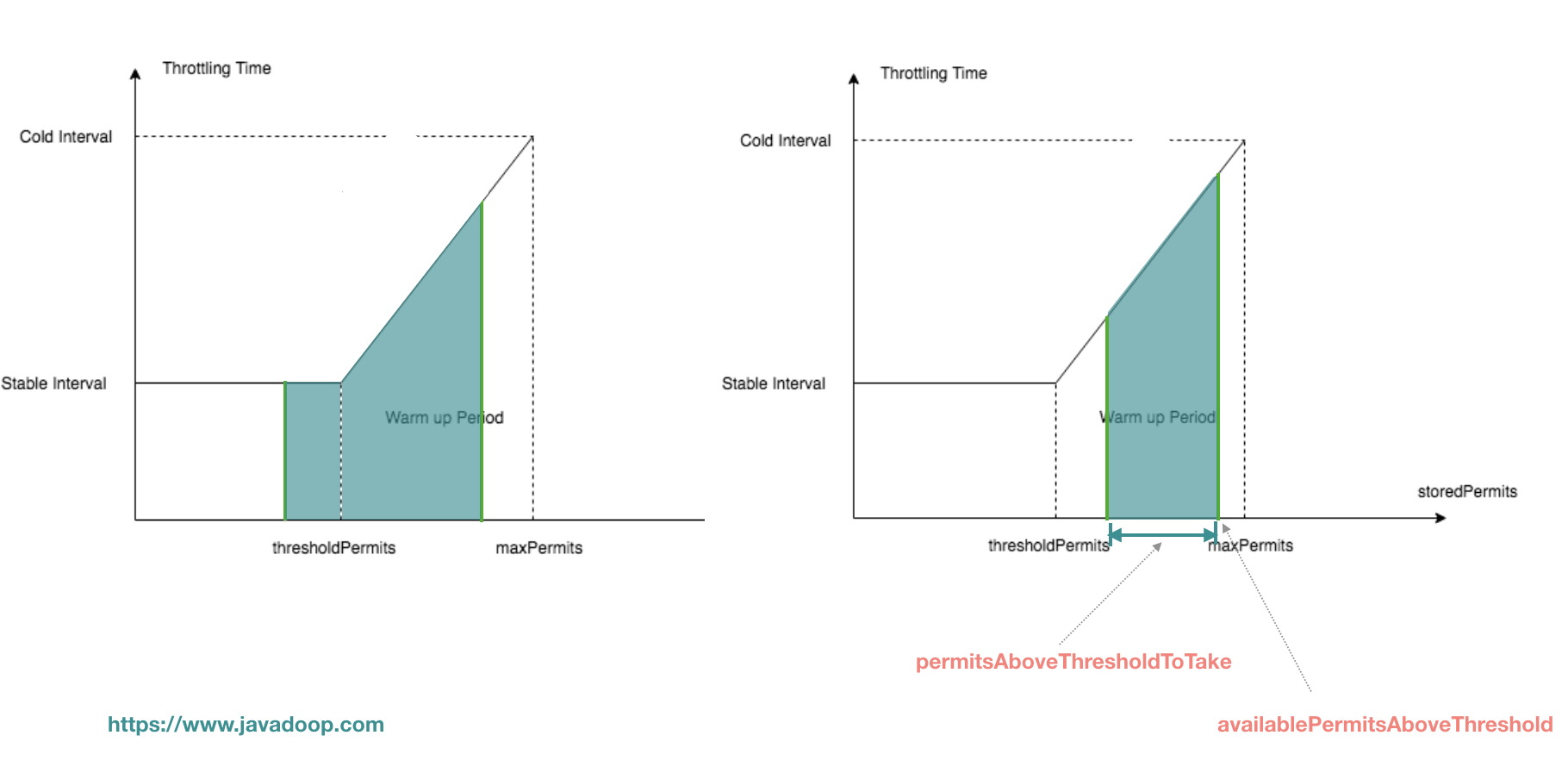
这段代码上面解释 acquire 的时候已经解释过了,它是 acquire 的核心,waitMicros 由两部分组成,一部分是从 storedPermits 中获取花费的时间,一部分是等待 freshPermits 产生花费的时间。在 SmoothBursty 的实现中,从 storedPermits 中获取 permits 直接返回 0,不需要等待。而在 SmoothWarmingUp 的实现中,由于需要预热,所以从 storedPermits 中取 permits 需要花费一定的时间,其实就是要计算下图中,阴影部分的面积。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @Override long storedPermitsToWaitTime (double storedPermits, double permitsToTake) { double availablePermitsAboveThreshold = storedPermits - thresholdPermits; long micros = 0 ; if (availablePermitsAboveThreshold > 0.0 ) { double permitsAboveThresholdToTake = min(availablePermitsAboveThreshold, permitsToTake); double length = permitsToTime(availablePermitsAboveThreshold) + permitsToTime(availablePermitsAboveThreshold - permitsAboveThresholdToTake); micros = (long ) (permitsAboveThresholdToTake * length / 2.0 ); permitsToTake -= permitsAboveThresholdToTake; } micros += (long ) (stableIntervalMicros * permitsToTake); return micros; } private double permitsToTime (double permits ) { return stableIntervalMicros + permits * slope; }
到这里,SmoothWarmingUp 基本上说完了。
小结 按照我写文章的惯例,对这篇文章做一个小结。本文首先从限流算法说起,介绍了两种常见的限流算法,分别是 Leaky Bucket Algorithm(漏桶算法) 和 Token Bucket Algorithm(令牌桶算法);接着重点以 Token Bucket Algorithm 为例,讲了 Token Bucket Algorithm 的具体实现,即 Google Guava RateLimiter。Guava RateLimiter 有两种模式,应对突发流量的 SmoothBursty 和 可以预热的 SmoothWarmingUp。SmoothBursty 获取 permits 不需要等待,可以现在令牌桶中存入 permits,需要注意的是,这里 permits 的增长是一种匀速的状态,当有突发流量时,一次性可以从令牌桶获取多个 permits;而 SmoothWarmingUp 获取 permits需要一个预热的状态,这样设计的作用是,如果系统可以承受最大的 QPS 是1000,如果系统是冷的,让系统立即达到 1000 QPS 会拖垮系统,因此这个预热的过程可以有效的保护系统,具体表现为从令牌桶中获取 permits 等待的时间会随着令牌被消耗逐渐缩短,直至一个稳定的时间。
注:本篇是流量控制的第一篇,后面可能会单独写一篇文章聊一下 TCP 中滑动窗口实现的流量控制。
(全文完)