type Task struct { Id int// the map task or reduce task id WorkName string// the worker name TaskType TaskType // the task type, map or reduce Status TaskStatus // the task state Input []string// task input files, map task is only one input file Output []string// task output files, reduce task is only one output file }
type BaseInfo struct { nReduce int// the total number of reduce tasks taskMap map[TaskType][]*Task workerMap map[string]*WorkInfo }
type WorkInfo struct { name string lastOnlineTime time.Time }
// server start a thread that listens for RPCs from worker.go func(c *Coordinator) server() { rpc.Register(c) rpc.HandleHTTP() //l, e := net.Listen("tcp", ":1234") sockname := coordinatorSock() os.Remove(sockname) l, e := net.Listen("unix", sockname) if e != nil { log.Fatal("listen error:", e) } go http.Serve(l, nil) }
// call send an RPC request to the coordinator, wait for the response. // usually returns true, returns false if something goes wrong. funccall(rpcname string, args interface{}, reply interface{})bool { // c, err := rpc.DialHTTP("tcp", "127.0.0.1"+":1234") sockname := coordinatorSock() c, err := rpc.DialHTTP("unix", sockname) if err != nil { log.Fatal("dialing:", err) } defer c.Close()
// Cook up a unique-ish UNIX-domain socket name // in /var/tmp, for the coordinator. // Can't use the current directory since // Athena AFS doesn't support UNIX-domain sockets. funccoordinatorSock()string { s := "/var/tmp/5840-mr-" s += strconv.Itoa(os.Getuid()) return s }
// Worker is called by main/mrworker.go funcWorker(mapf func(string, string) []KeyValue, reducef func(string, []string)string) { // get the current workspace path workDir, _ := os.Getwd() w := WorkerS{ name: "worker_" + strconv.Itoa(rand.Intn(100000)), mapF: mapf, reduceF: reducef, workDir: workDir, }
// send the RPC to the coordinator for asking the task in a loop for { reply := callGetTask(w.name) if reply.Task == nil { // can not get the task, maybe all map tasks or all reduce task are running but not be finished // waiting to the next phase time.Sleep(time.Second) }
log.Printf("[Info]: Worker: Receive the task: %v \n", reply) var err error switch reply.Task.TaskType { case MapTask: err = w.doMap(reply) case ReduceTask: err = w.doReduce(reply) default: // worker exit log.Printf("[Info]: Worker name: %s exit.\n", w.name) return } if err == nil { callTaskDone(reply.Task) } } }
// callGetTask send RPC request to coordinator for asking task funccallGetTask(workName string) *GetTaskReply { args := GetTaskArgs{ WorkerName: workName, } reply := GetTaskReply{} ok := call("Coordinator.GetTask", &args, &reply) if !ok { log.Printf("[Error]: Coordinator.GetTask failed!\n") returnnil } return &reply }
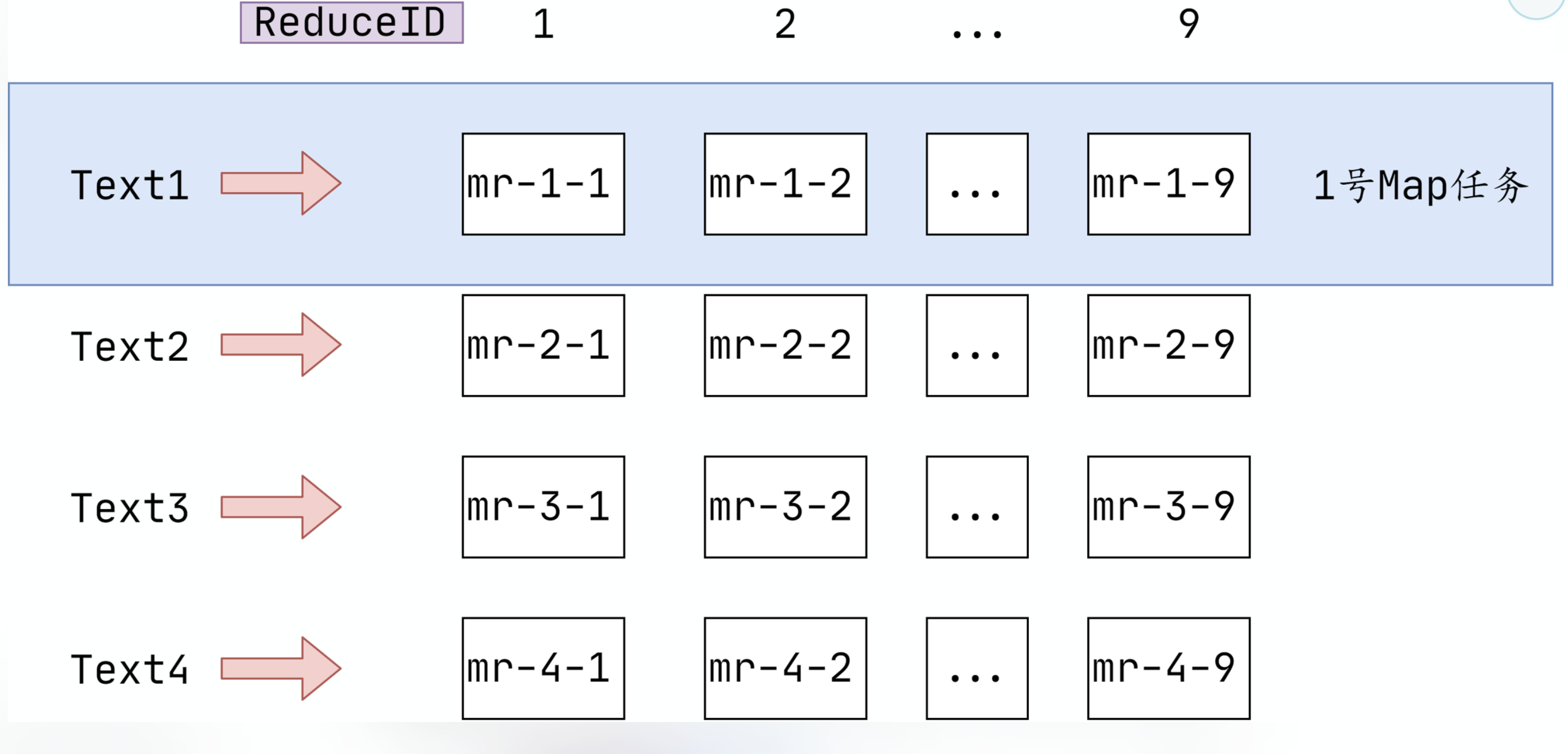
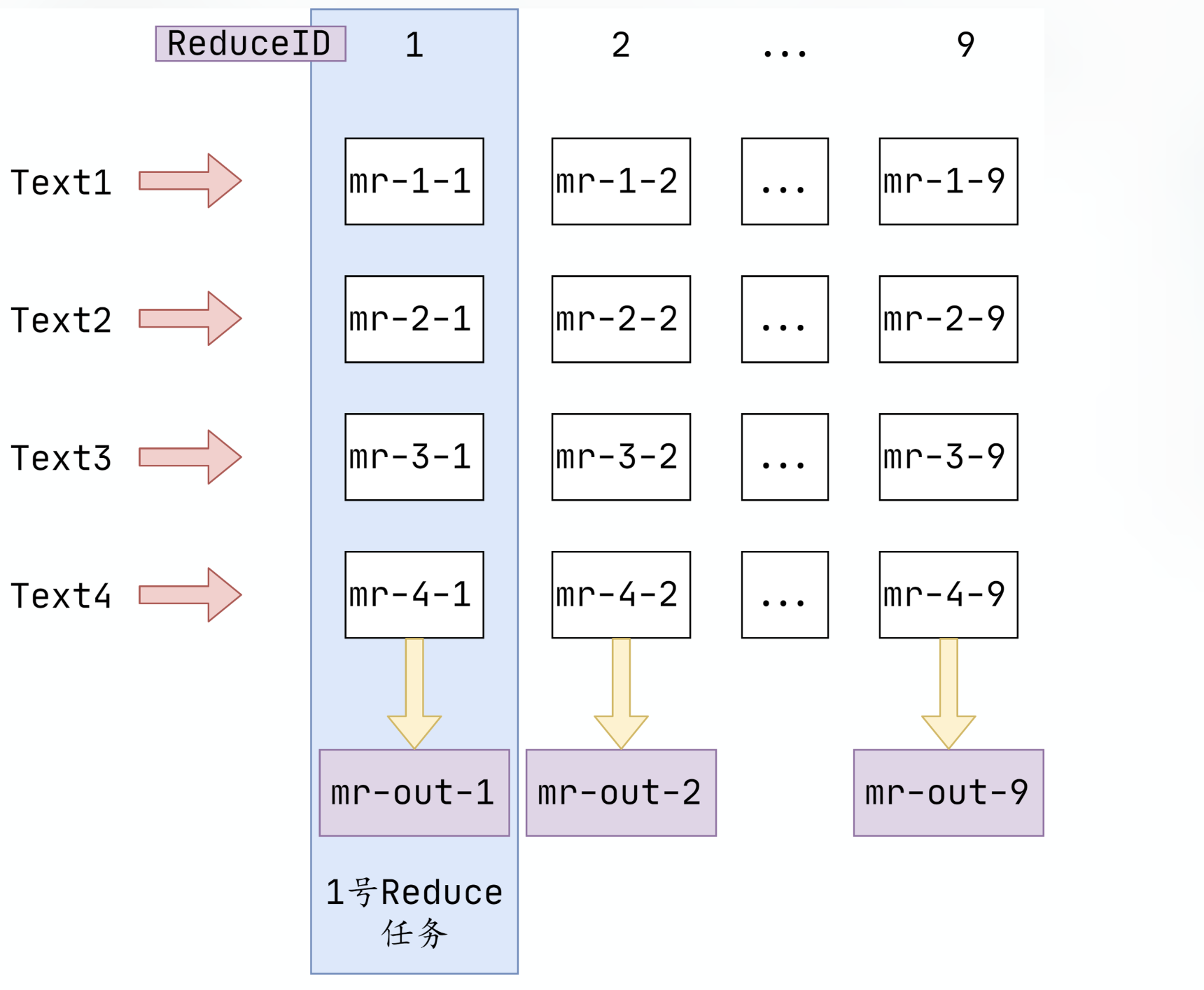
// kv2ReduceMap: key: reduce index, value: key/value list. split the same key into reduce kv2ReduceMap := make(map[int][]KeyValue, reply.NReduce) var output []string outputFileNameFunc := func(idxReduce int)string { return fmt.Sprintf("mr-%d-%d-temp-", task.Id, idxReduce) }
// call the map function kva := w.mapF(fileName, string(inputBytes)) for _, kv := range kva { idxReduce := ihash(kv.Key) % reply.NReduce kv2ReduceMap[idxReduce] = append(kv2ReduceMap[idxReduce], kv) }
for idxReduce, item := range kv2ReduceMap { // write to the temp file oFile, _ := os.CreateTemp(w.workDir, outputFileNameFunc(idxReduce)) encoder := json.NewEncoder(oFile) for _, kv := range item { err := encoder.Encode(kv) if err != nil { log.Printf("[Error]: write map task output file error: %v \n", err) _ = oFile.Close() break } } // rename index := strings.Index(oFile.Name(), "-temp") _ = os.Rename(oFile.Name(), oFile.Name()[:index]) output = append(output, oFile.Name()) _ = oFile.Close() }
// workerTimer create a timer that checks the worker online status every 1 second func(c *Coordinator) workerTimer() { gofunc() { ticker := time.NewTicker(time.Second) defer ticker.Stop()
for _, workInfo := range c.baseInfo.workerMap { if time.Now().Sub(workInfo.lastOnlineTime) <= 10 { continue } // According to the MapReduce paper, in a real distributed system, // since the intermediate files output by the Map task are stored on their respective worker nodes, // when the worker is offline and cannot communicate, all map tasks executed by this worker, // whether completed or not, should be reset to the initial state and reallocated to other workers, // while the files output by the reduce task are stored on the global file system (GFS), // and only unfinished tasks need to be reset and reallocated. if c.phase == MapPhase { mapTasks := c.baseInfo.taskMap[MapTask] for _, task := range mapTasks { if task.WorkName == workInfo.name { task.Status = Waiting task.WorkName = "" task.Output = []string{} } } } elseif c.phase == ReducePhase { reduceTasks := c.baseInfo.taskMap[ReduceTask] for _, task := range reduceTasks { if task.WorkName == workInfo.name && task.Status == Running { task.Status = Waiting task.WorkName = "" task.Output = []string{} } } } delete(c.baseInfo.workerMap, workInfo.name) } c.mutex.Unlock() } } }() }