go feed 介绍
上篇文章记录了我在服务器上搭建了自己的 RSS 服务,经过一段时间的体验使用,我发现 RSS 这种信息获取的方式的确很适合我。在深入使用的过程中,也逐渐总结了一些 tt-rss 的优缺点,先说我认为好的方面:
- 丰富的主题
- 完善的插件系统
- 支持独立部署
- 功能齐全
同时我也认为它有不好的地方(个人主观观点):
- PHP 驱动实现,稍有笨重,不够”现代化“
- 虽然有较为丰富的主题,但整体 UI 风格不是特别喜欢
- 用户系统不够完善,可玩性不高
- 不支持除 RSS 订阅以外的形态,例如:网页、文章阅读清单功能
基于上述,我决定自己开始探索这种类 RSS 阅读器的产品形态,自己做一个类 RSS 阅读器。
目前,大部分的博客网站都是支持 RSS 的,不支持 RSS 的网站,也有 RSS Hub 这样的产品帮助我们解决问题。RSS 文件订阅类型一般有 rss、atom、json类型,文件格式为 XML 和 JSON。网站将网站的内容信息整合到一个 RSS 文件中,这个文件我们一般称为 feed,也叫信源。在 RSS 文件里面具体包含了网站的标题、描述、作者信息、文章列表等信息,并且随着网站内容更新,RSS 文件也会随之更新,因此 RSS 阅读器通过定时解析 RSS 文件,就可以知道我们关注的网站有更新,实现了信息聚合。因此,最重要的过程就变成了两部分:
- 生成 RSS 文件,搞定信息来源
- 解析 RSS 文件,搞定信息展示
对于第 1 点来说,除了网站自身会提供 RSS 文件之外,也有诸如 RSS Hub 这样的项目,来帮助我们实现生成网站的 RSS 文件。第二部分,就是实现一个 RSS 阅读器的关键。这个过程本质不难,就是解析 RSS 文件,它们往往基于 XML 格式或者 JSON 格式,所以理论上我们只要解析到 XML 的 item 或者解析到 JSON 的节点,就能获取 RSS 文件的内容,从而获取网站的内容。
RSS 内容解析
在这之前,我们要搞清楚 RSS 文件都包含哪些内容,哪些内容是我们需要的,可以使用标准库来解析 XML 或者 JSON,当然 go 生态里面也有不少库已经帮我们做了这部分功能,这里我选择使用 gofeed 来解析 RSS 文件。
前面说到 RSS 文件有几种不同的类型,其中 rss 和 atom 类型都是基于 XML 格式的。例如 阮一峰的网络日志 就是 rss 类型的,云风 的博客就是 atom 类型的,通过例子也比较容易看出两种类型的区别。
gofeed 解析 RSS 文件,用法也比较简单,下面是几种常见的用法:
1 | // parse feed from a rss URL |
1 | // parse feed from String(XML or JSON) |
1 | // parse feed from file(io.Reader) |
上面代码示例可以看到,我们最终解析到的都是一个 feed 对象,那么这个 feed 结构体具体包含哪些内容呢,不同的 RSS 文件类型有什么区别呢,下面结合 gofeed 结构体中的定义具体说明。
rss 类型
1 | // Feed is an RSS Feed |
上面的结构体属性较多,我们只需要关注几个即可
Title:通常是网站的标题
Link:网站的 url 地址
Links:网站的链接集合,通常包含网站的 url,网站订阅链接的 URL 等
Description:网站的描述
Items:注意看,这也是一个结构体,它就是我们解析的网站的内容集合,我们 RSS 阅读器就是要解析这部分内容,并把它每一个节点内容展示出来。
点开 Items,它的结构属性如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// Item is an RSS Item
type Item struct {
Title string `json:"title,omitempty"`
Link string `json:"link,omitempty"`
Links []string `json:"links,omitempty"`
Description string `json:"description,omitempty"`
Content string `json:"content,omitempty"`
Author string `json:"author,omitempty"`
Categories []*Category `json:"categories,omitempty"`
Comments string `json:"comments,omitempty"`
Enclosure *Enclosure `json:"enclosure,omitempty"`
Enclosures []*Enclosure `json:"enclosures,omitempty"`
GUID *GUID `json:"guid,omitempty"`
PubDate string `json:"pubDate,omitempty"`
PubDateParsed *time.Time `json:"pubDateParsed,omitempty"`
Source *Source `json:"source,omitempty"`
DublinCoreExt *ext.DublinCoreExtension `json:"dcExt,omitempty"`
ITunesExt *ext.ITunesItemExtension `json:"itunesExt,omitempty"`
Extensions ext.Extensions `json:"extensions,omitempty"`
Custom map[string]string `json:"custom,omitempty"`
}这一部分,还是挑几个重要的属性说:
- Title:这里的 Title 代表的是文章标题
- Link:文章的 url 地址
- Description:文章的概要描述
- Content:文章的完整内容
值得一提的是,不同的 RSS 服务提供方,这里面的字段会有稍微差别,比如说,有些网站提供的 RSS 订阅就只有 Description,没有 Content 属性(或者 Content 属性跟 Description 内容一样,并没有显示文章完整内容),所以你会看到在 RSS 阅读器上,有的订阅是可以完整显示内容的,有的只是显示了摘要,需要你点击到原网站才能看到完整的内容。比如 美团技术团队 的 RSS 文件,它的 Content 就不完整,你在 tt-rss 里面看到的就是这个样子
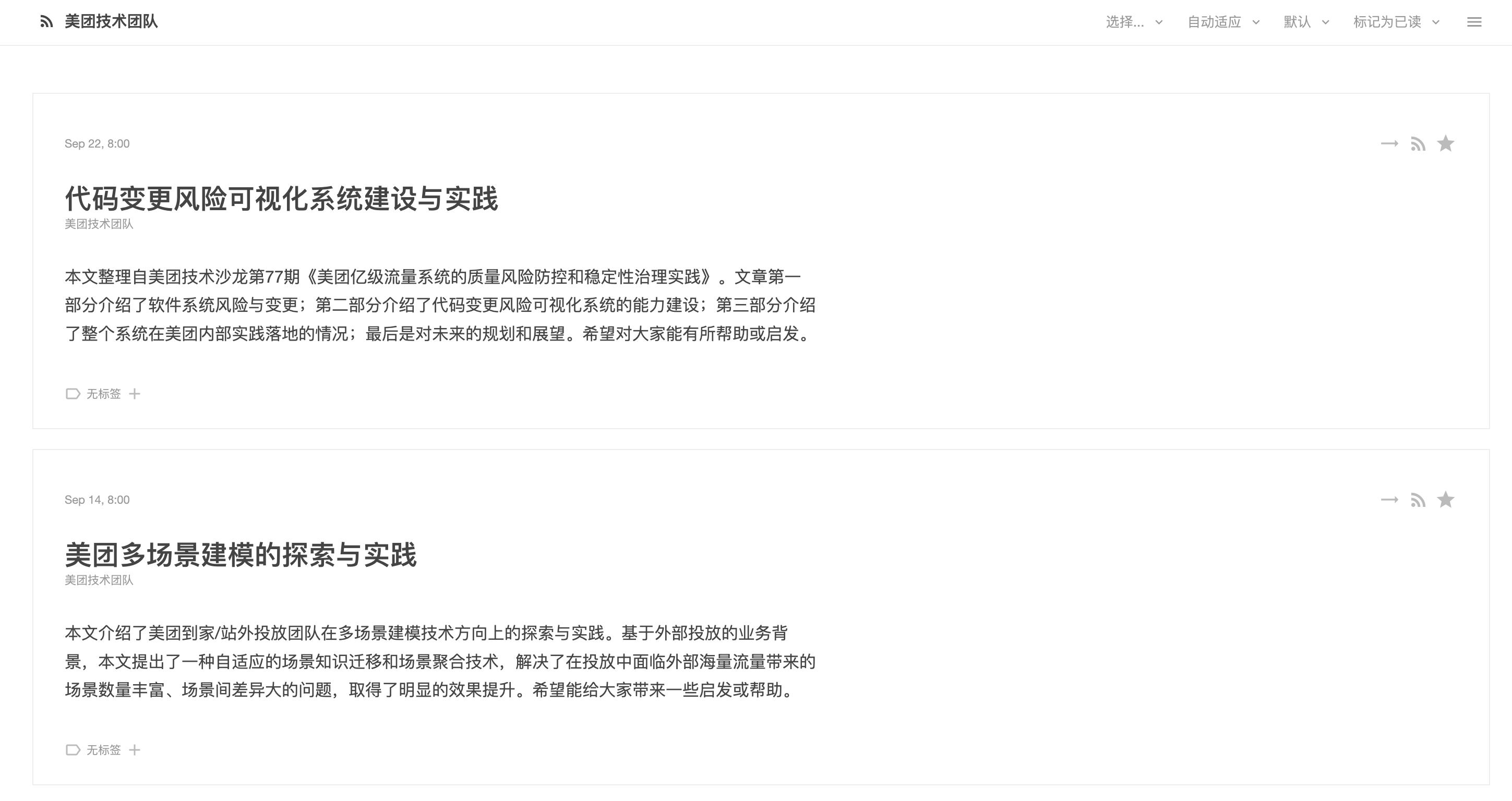
关于这一部分不能解析到完整内容的 RSS 文件,我将在后面单独说。
atom 类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// Feed is an Atom Feed
type Feed struct {
Title string `json:"title,omitempty"`
ID string `json:"id,omitempty"`
Updated string `json:"updated,omitempty"`
UpdatedParsed *time.Time `json:"updatedParsed,omitempty"`
Subtitle string `json:"subtitle,omitempty"`
Links []*Link `json:"links,omitempty"`
Language string `json:"language,omitempty"`
Generator *Generator `json:"generator,omitempty"`
Icon string `json:"icon,omitempty"`
Logo string `json:"logo,omitempty"`
Rights string `json:"rights,omitempty"`
Contributors []*Person `json:"contributors,omitempty"`
Authors []*Person `json:"authors,omitempty"`
Categories []*Category `json:"categories,omitempty"`
Entries []*Entry `json:"entries"`
Extensions ext.Extensions `json:"extensions,omitempty"`
Version string `json:"version"`
}这是 atom 类型的结构体属性,大部分字段跟上面的 rss 类型差不多,不同的就是网站内容部分这里是 Entry,点开 Entry 属性,结构体属性如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// Entry is an Atom Entry
type Entry struct {
Title string `json:"title,omitempty"`
ID string `json:"id,omitempty"`
Updated string `json:"updated,omitempty"`
UpdatedParsed *time.Time `json:"updatedParsed,omitempty"`
Summary string `json:"summary,omitempty"`
Authors []*Person `json:"authors,omitempty"`
Contributors []*Person `json:"contributors,omitempty"`
Categories []*Category `json:"categories,omitempty"`
Links []*Link `json:"links,omitempty"`
Rights string `json:"rights,omitempty"`
Published string `json:"published,omitempty"`
PublishedParsed *time.Time `json:"publishedParsed,omitempty"`
Source *Source `json:"source,omitempty"`
Content *Content `json:"content,omitempty"`
Extensions ext.Extensions `json:"extensions,omitempty"`
}这种 atom 类型下,Summary 表示的就是网站概要总结,Content 表示的就是网站的完整内容。
json 类型
Json 类型跟字段属性跟上面两种类型差别不大,由于平时本人见的也不多,这里就不贴代码了,具体的代码见 gofeed 仓库。
gofeed 支持
说完上述三种类型的 RSS 订阅文件,再来看一下 gofeed 的支持。gofeed 对这三种类型的 RSS 订阅文件也都有直接的支持。
1
2
3
4
5
6
7
8
9
10// RSS Feed
feedData := `<rss version="2.0">
<channel>
<webMaster>example@site.com (Example Name)</webMaster>
</channel>
</rss>`
fp := rss.Parser{}
rssFeed, _ := fp.Parse(strings.NewReader(feedData))
fmt.Println(rssFeed.WebMaster)1
2
3
4
5
6
7
8// Atom Feed
feedData := `<feed xmlns="http://www.w3.org/2005/Atom">
<subtitle>Example Atom</subtitle>
</feed>`
fp := atom.Parser{}
atomFeed, _ := fp.Parse(strings.NewReader(feedData))
fmt.Println(atomFeed.Subtitle)1
2
3
4
5
6// JSON Feed
feedData := `{"version":"1.0", "home_page_url": "https://daringfireball.net"}`
fp := json.Parser{}
jsonFeed, _ := fp.Parse(strings.NewReader(feedData))
fmt.Println(jsonFeed.HomePageURL)这些用法在 gofeed 官方仓库都有对应说明
no Content 的场景
上面说到,有些订阅的 RSS 文件,并没有网站的完整内容,对于这种场景,应该如何解析呢?
普遍的做法是类似 tt-rss 这样,在没有 Content 的情况下,解析 Description 显示,只显示内容摘要,可以通过点击标题进原地址看完整内容。在这种情况下,如果我想解析到网站完整的内容并且直接在 RSS 阅读器中展示应该怎么办呢?
- 容易想到,一种方式可以通过文章的原文链接,爬取原文网页上的内容。这种通过爬虫的方式,及其不稳定,主要涉及到不同网站样式布局会有不同的表现,需要针对不同的网站的 RSS 文件做单独适配。
- 另外一种,我有考虑过在 RSS 阅读器的内容显示区域,直接调用浏览器的能力根据原文地址链接直接渲染原网页。
上面两种方式是我一开始就想到的方式,但是在我看来,这两种方式实现起来并不优雅,似乎不是一个好的解决方案,所以这两种方式我现阶段并没有去做验证和调研。在写这篇文章的时候,我突然想到现在 AI 大模型这么火,这个场景是不是能接入大模型实现的更优雅一点呢?比如说,对这种无法解析完整文章内容的场景,我可以借助原文的地址链接让 AI 大模型总结提取文章内容(互联网接入功能),我知道的目前 Microsoft Bing Chat 是提供互联网接入功能的,尝试了一下是可以读取原文完整内容的。
最后,对于这种利用 AI 大模型的做法,我接下来应该会详细做一个验证,到时候可能会单独写一篇文章讲述整个验证过程,证明其是否具有可行性。
(本文完)





